介绍
对大多数用户来说,ETL的核心价值在T所代表的转换部分。这个阶段要做很多工作,数据清洗就是其中一项重点任务。数据清洗是对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。
处理脏数据
数据仓库中的数据是面向某一主题数据的集合,这些数据从多个业务系统中抽取而来,并且包含历史数据,因此就不可避免地出现某些数据是错误的,或者数据相互之间存在冲突的情况。这些错误的或有冲突的数据显然不是我们想要的,被称为“脏数据”。我们要按照一定的规则处理脏数据,这个过程就是数据清洗。数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果交给业务主管部门,确认是直接删除掉,还是修正之后再进行抽取。
不符合要求的数据主要是残缺的数据、错误的数据、重复的数据、差异的数据四大类。
- 残缺数据
- 这一类数据主要是一些应该有的信息缺失,如产品名称、客户名称、客户的区域信息,还包括业务系统中由于缺少外键约束所导致的主表与明细表不能匹配等。
- 错误数据
- 这一类错误产生的原因多是业务系统不够健全,在接收输入后没有进行合法性检查或检查不够严格,将有问题的数据直接写入后台数据库造成的,比如用字符串存储数字、超出合法的取值范围、日期格式不正确、日期越界等。
- 重复数据
- 源系统中相同的数据存在多份。
- 差异数据
- 本来具有同一业务含义的数据,因为来自不同的操作型数据源,造成数据不一致。这时需要将非标准的数据转化为在一定程度上的标准化数据。
数据清洗原则
- 保障数据清洗处理顺利进行的原则是优先对数据清洗处理流程进行分析和系统化的设计,针对数据的主要问题和特征,设计一系列数据对照表和数据清洗程序库的有效组合,以便面对不断变化的、形形色色的数据清洗问题。数据清洗流程通常包括如下内容。
- 预处理
- 对于大的数据加载文件,特别是新的文件和数据集合,要进行预先诊断和检测,不能贸然加载。有时需要临时编写程序进行数据清洁检查。
- 标准化处理
- 应用建于数据仓库内部的标准字典,对于地区名、人名、公司名、产品名、分类名以及各种编码信息进行标准化处理。
- 查重
- 应用各种数据库查询技术和手段,避免引入重复数据。
- 出错处理和修正
- 将出错的记录和数据写入到日志文件,留待进一步处理。
实例
身份证号码检查
身份证号码格式校验是很多系统在数据集成时的一个常见需求,我们以18位身份证为例,使用一个Hive查询实现身份证号码的合法性验证。该查询结果是所有不合规的身份证号码。按以下身份证号码的定义规则建立查询。
身份证18位分别代表的含义,从左到右方分别表示:
1~2,省级行政区代码。
3~4,地级行政区划分代码。
5~6,县区行政区分代码。
7~10、11~12、13~14,出生年、月、日。
15~17,顺序码,同一地区同年、同月、同日出生人的编号,奇数是男性,偶数是女性。
18校验码,如果是0~9则用0~9表示,如果是10则用X(罗马数字10)表示。
验证码计算方法
将前面的身份证号码17位数分别乘以不同的系数。从第1位到第17位的系数分别为:7-9-10-5-8-4-2-1-6-3-7-9-10-5-8-4-2。
将这17位数字和系数相乘的结果相加。
用加出来和除以11,看余数是多少。
余数只可能有0-1-2-3-4-5-6-7-8-9-10这11个数字。其分别对应的最后一位身份证的号码为1-0-X -9-8-7-6-5-4-3-2。
首先建立test表
create table test(idcard varchar(64));
insert into test values("453488808776763114");
insert into test values("500101545645553119");
insert into test values("437387322203063116");
简单的验证代码
select * from
(select trim(upper(idcard)) idcard from test) t1
where
length(idcard) <>18
or substr(idcard,1,2) not in
('11','12','13','14','15','21','22','23','31','32','33','34','35','36','37','41','42','43','44','45','46','50','51','52','53','54','61','62','63','64','65','71','81','82','91')
or substr('10X98765432',pmod(
(cast(substr(idcard,1,1) as int) + cast(substr(idcard,11,1) as int))*7
+(cast(substr(idcard,2,1) as int) + cast(substr(idcard,12,1) as int))*9
+(cast(substr(idcard,3,1) as int) + cast(substr(idcard,13,1) as int))*10
+(cast(substr(idcard,4,1) as int) + cast(substr(idcard,14,1) as int))*5
+(cast(substr(idcard,5,1) as int) + cast(substr(idcard,15,1) as int))*8
+(cast(substr(idcard,6,1) as int) + cast(substr(idcard,16,1) as int))*4
+(cast(substr(idcard,7,1) as int) + cast(substr(idcard,17,1) as int))*2
+cast(substr(idcard,8,1) as int)*1
+cast(substr(idcard,9,1) as int)*6
+cast(substr(idcard,10,1) as int)*3,11)+1,1)
<>cast(substr(idcard,18,1) as int);
直接可检查出无效的身份证号码:
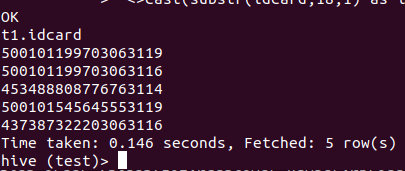
去除重复数据
有两个意义上的重复记录,一是完全重复的记录,也即所有字段均都重复,二是部分字段重复的记录。
- 对于第一种重复,比较容易解决,只需在查询语句中使用
distinct关键字去重,几乎所有数据库系统都支持distinct操作。发生这种重复的原因主要是表设计不周,通过给表增加主键或唯一索引列即可避免。
use test;
drop table if exists test;
create table test(c1 int, c2 int);
insert into test values(1,1);
insert into test values(2,2);
insert into test values(1,1);
select * from test;
select distinct * from test;
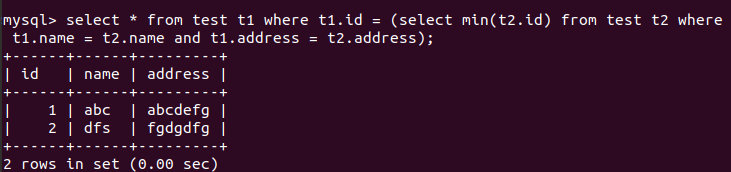
- 对于第二类重复问题,通常要求查询出重复记录中的任一条记录。假设表t有id、name、address三个字段,id是主键,有重复的字段为name、address,要求得到这两个字段唯一的结果集。
drop table if exists test;
create table test(id int,name varchar(10),address varchar(20));
insert into test values(1,'abc','abcdefg');
insert into test values(2,'dfs','fgdgdfg');
insert into test values(3,'dfs','fgdgdfg');
select * from test t1 where t1.id = (select min(t2.id) from test t2 where t1.name = t2.name and t1.address = t2.address);
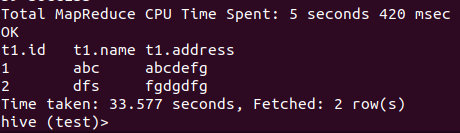
- Hive支持在FROM子句中使用子查询,子查询必须有名字,并且列必须唯一(也支持子查询)
drop table if exists test;
create table test(id int,name varchar(10),address varchar(20));
insert into test values(1,'abc','abcdefg');
insert into test values(2,'dfs','fgdgdfg');
insert into test values(3,'dfs','fgdgdfg');
select t1.* from test t1, (select name,address,min(id) id from test group by name,address) t2 where t1.id = t2.id;
- 还可以使用Hive的row_number()分析函数
select test.id,test.name,test.address from (select id,name,address,row_number() over (distribute by name,address sort by id)as rn from test) test where test.rn=1;
清洗日志
创建源表
use test;
create table IF NOT EXISTS source_log (
remote_addr string,
remote_user string,
time_local string,
request string,
status string,
body_bytes_sent string,
request_body string,
http_referer string,
http_user_agent string,
http_x_forwarded_for string,
host string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "(\"[^ ]*\") (\"[-|^ ]*\") (\"[^\"]*\") (\"[^\"]*\") (\"[0-9]*\") (\"[0-9]*\") ([-|^ ]*) (\"[^ ]*\") (\"[^\"]*\") (\"[-|^ ]*\") (\"[^ ]*\")"
)
STORED AS TEXTFILE;
加载数据,先创建本地文件source.log,插入以下数据:
"27.38.5.159" "-" "31/Aug/2015:00:04:37 +0800" "GET /course/view.php?id=27 HTTP/1.1" "303" "440" - "http://www.ibeifeng.com/user.php?act=mycourse" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36" "-" "learn.ibeifeng.com"
"27.38.5.159" "-" "31/Aug/2015:00:04:37 +0800" "GET /login/index.php HTTP/1.1" "303" "465" - "http://www.ibeifeng.com/user.php?act=mycourse" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36" "-" "learn.ibeifeng.com"
执行命令:load data local inpath '/home/scott/Documents/source.log' into table source_log;
过滤字段(去掉每个字段的双引号)
create table clean_log(
remote_addr string,
time_local string,
request string,
http_referer string
)
row format delimited fields terminated by '\t'
stored as parquet tblproperties("parquet.compress"="SNAPPY");
insert into clean_log
select regexp_replace(remote_addr, '"', ''),
regexp_replace(time_local, '"', ''),
regexp_replace(request, '"', ''),
regexp_replace(http_referer, '"', '')
from source_log;
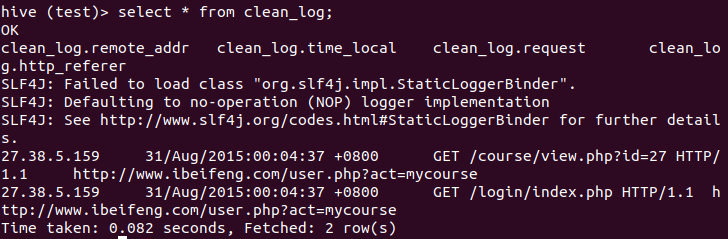
过滤字段(截取请求地址)
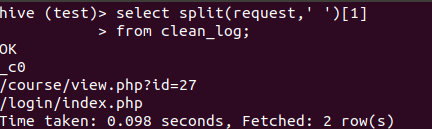
从 "GET /course/view.php?id=27HTTP/1.1" 中获取请求地址,即/course/view.php?id=27
select split(request,' ')[1]
from clean_log;
过滤字段(截取referer主地址)
从"http://www.ibeifeng.com/user.php?act=mycourse"提取主地址,即"http://www.ibeifeng.com"
select REGEXP_EXTRACT(http_referer, '^(?:.*://)?(?:www\.)?([^:/]*).*$', 1)
from source_log;
